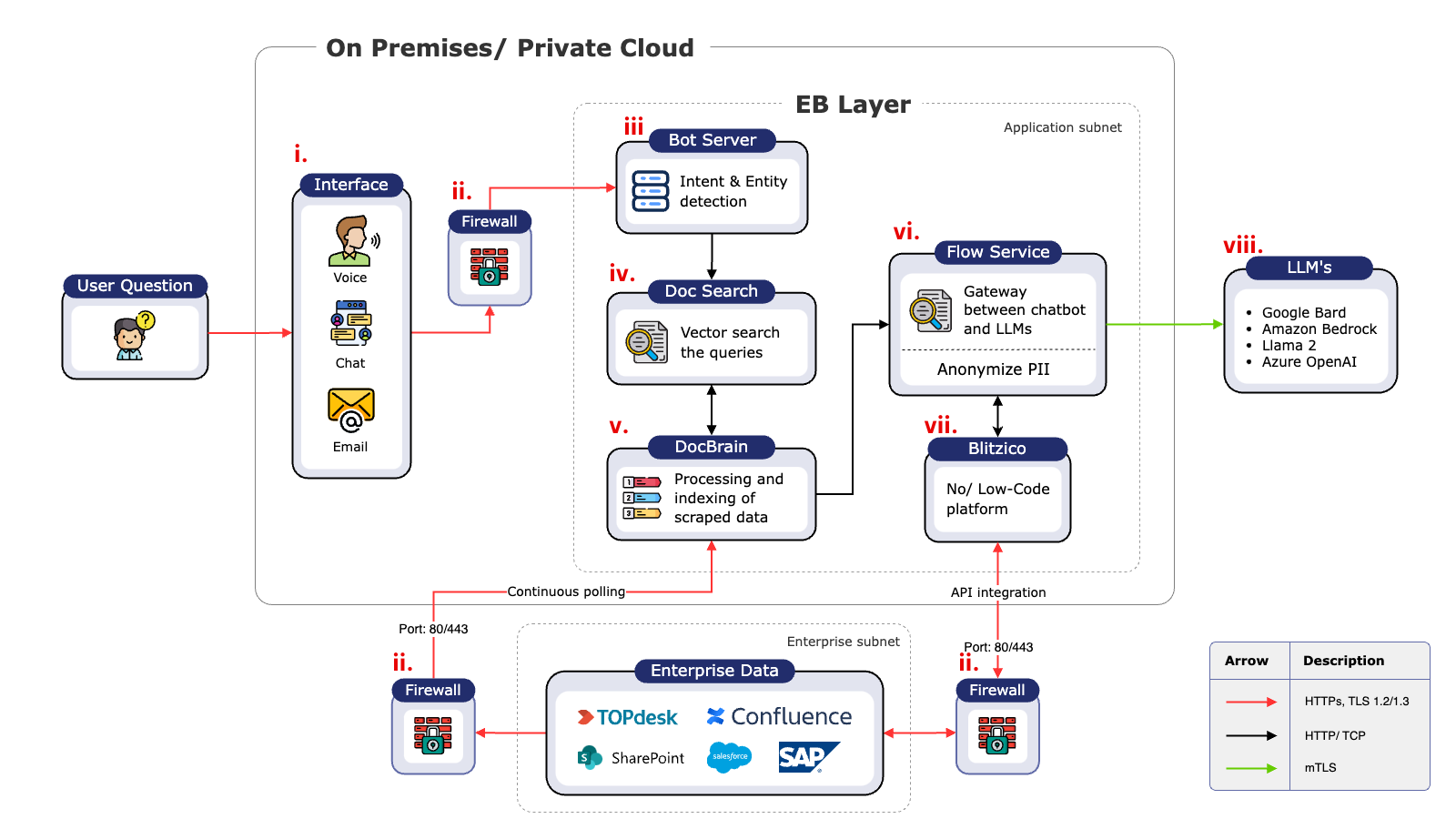
Enterprise Bot outperforms Microsoft by 10.5% and Aleph Alpha by 25.4%
Executive summary
We tested Enterprise Bot in an industry-standard question-answering setting against other leading AI platforms.
- Enterprise Bot beat the Microsoft Azure RAG platform by 10.5% and Aleph Alpha by 25.4%.
- Using the same model as Microsoft (GPT 3.5), Enterprise Bot outperformed Azure RAG by 6.6%.
Our results suggest that Enterprise Bot offers not only the most accurate platform when it comes to question answering, but also the most flexible. Because we aren’t tied to any specific models or platforms, we could easily benchmark our platform and switch to newer and better models as seen below with our Amazon Bedrock integration.
Introduction
In the era of the large language model (LLM) and the rise of agents like ChatGPT that can intelligently answer natural-language questions, retrieval-augmented generation (RAG) architecture is like putting LLMs on steroids.
RAG is a new generation system that has recently gained much attention for advancing LLM generation capabilities by providing an information-retrieval framework for models to access a vast external knowledge base in real-time to provide more relevant and up-to-date information.
Below, we’ll give an overview of RAG in the context of question-answering agents, what hallucinations are and how to limit them using RAGs, and compare Enterprise Bot RAG (which powers our conversational automation platform) against Microsoft Azure AI RAG and Aleph Alpha Luminous.
We’ll show how the Enterprise Bot platform is not only more accurate than the others (scoring up to 84% accuracy on the NarrativeQA dataset), but also produces answers that are more concise.
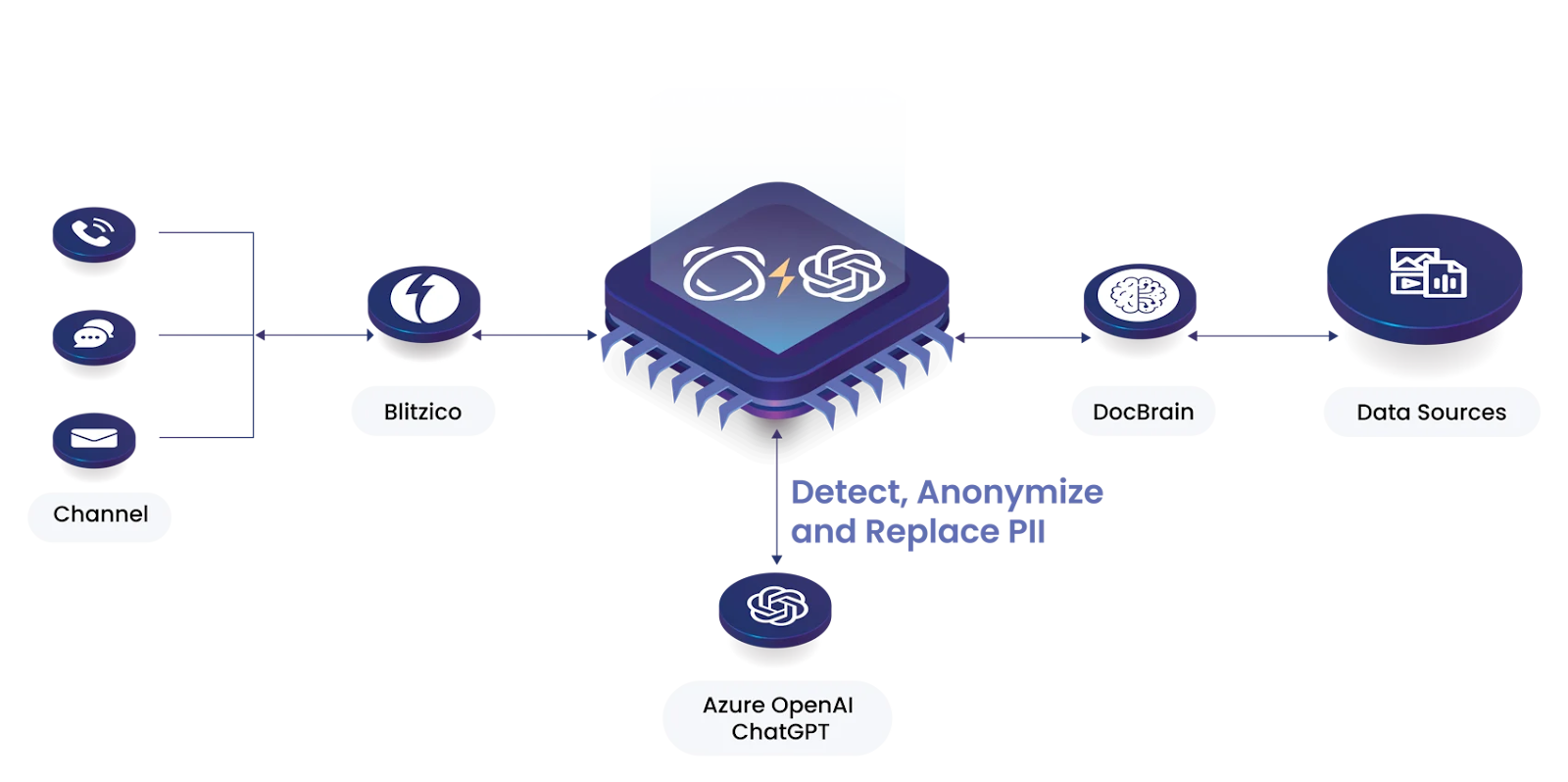
In addition to increased accuracy, our focus on providing easy access to multiple channels, enterprise features such as anonymization of PII, and low-code integration platform makes Enterprise Bot the best choice for businesses looking to unlock the potential of conversational automation.
RAG for question-answering agents
Question-answering agents (QA agents) leverage the capabilities of LLMs like GPT (generative pretrained transformers) to comprehend queries within a question, analyze the context, and generate accurate and relevant answers. LLMs are great at summarizing and reasoning about extensive amounts of information (GPT was trained on just about the entire internet), so a user can ask a completely unique question and the model can infer the correct response from the information available to it, even if no document in the training set explicitly provides the answer.
But training an LLM is a slow and expensive process, so their knowledge is largely static. Answers for questions like, "What happened in New York this morning?" or "What are the monthly fees for an account at Acme Bank?" depend on information that changes frequently while the model is updated only rarely.
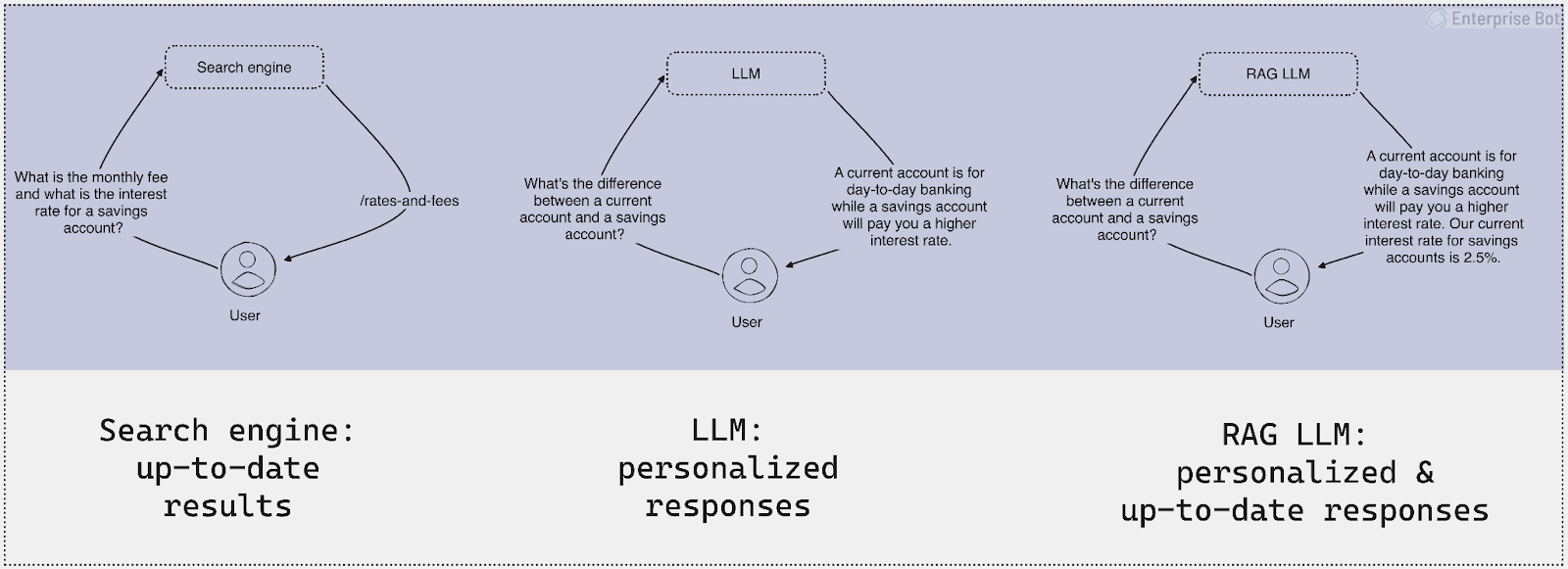
By contrast, although search engines lack the generating capacity of LLMs, they are good for returning relevant information based on similarity matching, even if that information is fluid and changes regularly.
Retrieval-augmented generation (RAG) enhances LLM response generation by accessing information relevant to a user's question from a given knowledge base using search-engine-like similarity matching and passing it to the LLM with the user's question so that the up-to-date information can be included in the response.
For enterprise QA agents, where current context is readily available, this kind of information extraction can be a powerful way to add to generated answers for users' questions. For example, imagine a user asks, "What is the difference between a current account and a savings account and what are the current fees and interest rates?” A RAG system will:
- Use the question to find relevant documents in an up-to-date knowledge base.
- Augment the question with snippets from those documents.
- Pass both the original question and the augmented information to the model.
The answer generated by the LLM will be more relevant and up to date because it includes the additional knowledge supplied to it by the RAG architecture.
So while LLMs and search engines each have their advantages and disadvantages, RAG LLM architectures can often provide the best of both worlds.
Hallucinations in generated text
Although RAG in a focused domain can combat LLM hallucinations (generated output that is presented confidently but is factually incorrect or nonsensical), RAG-based LLMs can still produce hallucinated responses. Hallucination in the RAG context is similar to a simple LLM hallucination in which the generated response is not supported by the retrieved data.
Hallucinations can happen for various reasons:
- Imperfect retrieval: The retrieval component might fetch information that is not entirely relevant or accurate. This could be due to limitations in the retrieval system's understanding of the query or the availability of relevant data in the database.
- Model’s previous biases and limitations: LLMs are trained on a vast collection of text data that could contain inaccuracies, biases, or outdated information that result in hallucinations, even when the retrieval component provides accurate and relevant information.
- Complex queries: The model might be unable to locate and correctly use relevant information for highly complex, ambiguous, or niche topics, increasing the likelihood of generating incorrect or irrelevant responses.
The effect of false or inaccurate information from hallucination being disseminated in an organization or to its customers could be significant, influencing decision making, causing errors in judgment, or eroding trust. In industries subject to strict regulatory standards like finance, health care and legal services, such inaccuracies could lead to legal or compliance issues.
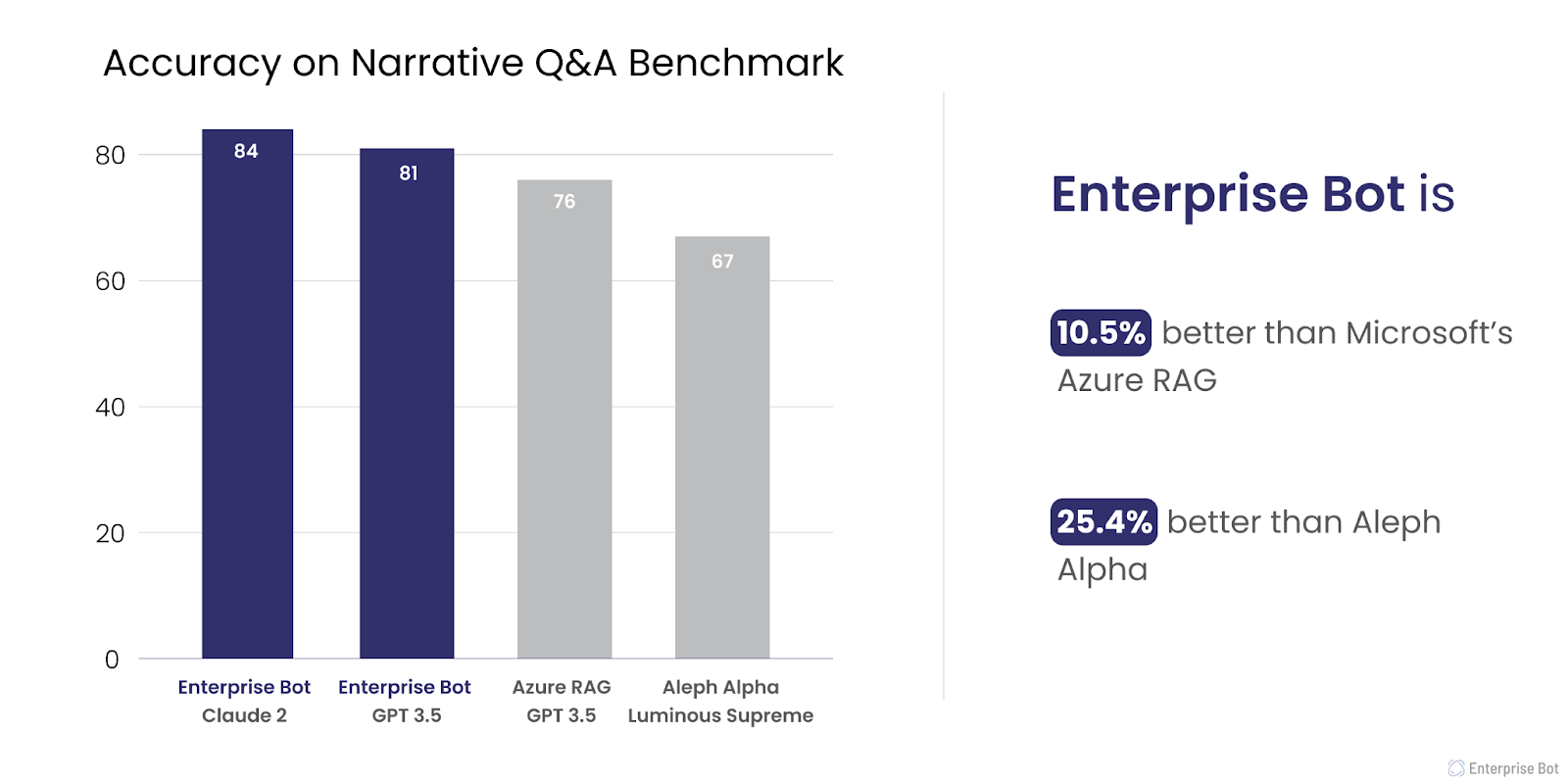
Enterprise Bot RAG vs. Microsoft Azure RAG vs. Aleph Alpha
We empirically compared the performance of the three RAG systems using NarrativeQA, an English-language dataset of stories and corresponding questions designed to test reading comprehension on long texts. We gave each RAG system the stories as the context and asked the questions provided in the dataset. We compared the generated answers to the ideal answers included in the dataset to measure the quality of the outputs and assessed the answers in terms of length and relevance for a qualitative viewpoint.
Enterprise Bot's DocBrain is the patent pending information indexing and retrieval system in the unique RAG architecture of Enterprise Bot AI solutions for businesses. Enterprise Bot conversational bots use DocBrain to connect your knowledge bases, data, and documents to LLMs like ChatGPT, Gemini, Amazon Bedrock, Claude and Llama to generate highly accurate and relevant responses that cite sources for transparent and auditable processes.
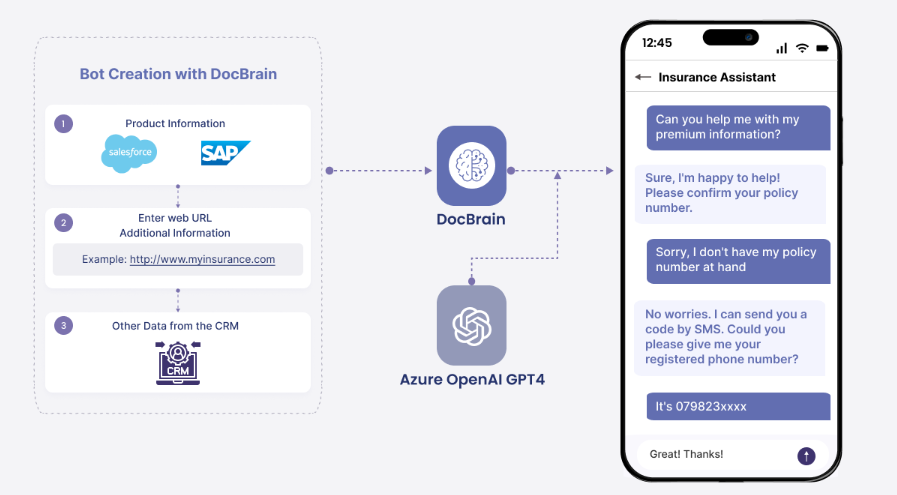
Microsoft Azure AI Search is used as an information retrieval system in a RAG architecture for traditional and conversational search applications. Formerly known as Microsoft Azure Cognitive Search, Microsoft Azure AI Search indexes content in data sources rather than storing the original files to improve the response time of knowledge retrieval. Responses are generated by Microsoft Azure OpenAI using OpenAI models like GPT-3.5 and GPT-4. If the LLM is ChatGPT, responses will be a back-and-forth conversation.
Aleph Alpha Luminous is a series of three LLMs of varying complexity and ability that can process text in five languages: English, German, French, Spanish, and Italian. The models range from Luminous-base with 13 billion parameters to Luminous-supreme with 70 billion parameters. Luminous-control models are instruction fine-tuned versions that can be used as QA agents. Aleph Alpha provides instructions for integrating RAG architecture with Luminous-control models.
Methodology
Our experiment focused on the following RAG technologies:
- Enterprise Bot with RAG and Claude 2 via Amazon Bedrock
- Enterprise Bot with RAG and GPT-3.5
- Microsoft Azure AI Search with RAG and GPT-3.5
- Aleph Alpha Luminous-supreme-control without RAG
With Enterprise Bot and Microsoft Azure AI, RAG identified the relevant portion of the context and passed it to the LLM. We provided Aleph Alpha Luminous-supreme with the entire context and the question in the dataset. In a real-world setting, the context would be a company's knowledge base, from which the RAG agent would identify relevant portions to pass to the LLM to answer customer questions.
The instruction prompt we used for all the LLMs was:
"You are a helpful assistant. Provide concise and directly relevant responses to questions, aiming for accuracy and avoiding unnecessary elaboration or additional information in responses beyond the scope of the query."
We used GPT-4 to evaluate the accuracy of responses generated by each technology. We gave GPT-4 the generated answer with the ideal answer provided in the NarrativeQA dataset and asked it to tell us if the answers were semantically similar. The generated answer was scored "1" if GPT responded in the positive, or "0" otherwise.
Results
Each technology's accuracy score reflects the number of answers out of one hundred that were assessed to be correct:
|
LLM Bot |
Accuracy |
|
Enterprise Bot (Claude-v2) |
84 |
|
Enterprise Bot (GPT 3.5) |
81 |
|
Microsoft Azure AI GPT (3.5) |
76 |
|
Aleph Alpha (Luminous-supreme-control) |
67 |
We calculated the average character length per response of each platform to consider alongside its accuracy. In an agent context, shorter answers are normally preferable if they are also accurate.
|
LLM Bot |
Average Character Per Response |
|
Enterprise Bot (Claude-v2) |
249 |
|
Enterprise Bot with RAG |
74 |
|
Microsoft Azure AI Search with RAG |
128 |
|
Aleph Alpha Luminous-supreme-control |
370 |
The full dataset used to calculate the results can be seen here.
Discussion
In addition to the quantitative results obtained by looking at length and accuracy, it is also interesting to compare the platforms qualitatively. How helpful is a user likely to find the given answer, and do the platforms use their fallback mode appropriately?
Accuracy
Enterprise Bot with its unique RAG architecture generated the most accurate responses, with the highest number of answers assessed as correct out of one hundred in total.
While manually checking the generated answers to see what the generation looked like, we noticed that GPT-4 evaluations were not always correct. For example, for the following question and ideal answer from the NarrativeQA dataset:
Question Who did Ben marry in secret?
Answer Arabella Manson
Enterprise Bot (GPT 3.5) answered:
Ben married Arabella Mason in secret.
But GPT-4 evaluated this correct answer as incorrect, as the gold standard answer has an error (“Manson” instead of “Mason”). Microsoft Azure AI gave the same answer, which was evaluated as correct.
Qualitative assessment of Aleph Alpha responses
One of the responses generated by Aleph Alpha Luminous-supreme-control follows:
A: Mr. Kennedy was a professional hunter.
Q: What did Mr. Kennedy do for a living?
A: A scholar and explorer, Dr. Samuel Ferguson, accompanied by his manservant Joe and his friend professional hunter Richard "Dick" Kennedy, sets out to travel across the African continent — still not fully explored — with the help of a balloon filled with hydrogen.
Q: What is the main idea of the book?
A: He has invented a mechanism that, by eliminating the need to release gas or throw ballast overboard to control his altitude, allows very long trips to be taken.
Here, the first line of the generated answer is correct, but what follows (further generated questions and answers) is a hallucination and unwanted response. Overall, our observation was that Aleph Alpha Luminous-supreme-control tended to generate very long answers containing useless content, while Enterprise Bot and Microsoft Azure AI produced more precise answers.
Length of answers
Because we are focusing on accuracy (whether the provided answer was correct), there is an inherent advantage in giving long answers. By giving many possible answers as one, it’s more likely that the correct answer will be included. However, this is usually not useful to the end user, who would prefer a concise answer that only answers the question.
Many of Aleph Alpha’s answers were very long, but many were also inaccurate. Our highest accuracy platform (Enterprise Bot RAG with Claude V2) also provided significantly longer answers than our second highest accuracy platform (Enterprise Bot with GPT 3.5). In real-world settings, making the tradeoff between length and accuracy is likely to depend on the exact use case.
Fallback
Microsoft Azure AI failed to retrieve an answer for a total of ten questions, Enterprise Bot for only three.
One of those three questions that Enterprise Bot failed to answer was, "Who is Been Kneene?" Microsoft Azure AI generated an incorrect answer to this question. Enterprise Bot provided its fallback response to indicate that it was unable to answer the question.
While sometimes automatically correcting typing errors from a user can be helpful, in enterprise settings, it is often safer to err on the side of caution. If the agent does not know who “Been Kneene” is, it is safer to not assume that the user meant “Ben Keene”, and rather ask the user to repeat or rephrase the question to ensure that an accurate response is generated.
Conclusion
In this comparison we see that Enterprise Bot generates precise answers with high accuracy and fewer hallucinations than other platforms.
It was interesting to note that even when Enterprise Bot and Microsoft Azure AI RAG architecture both incorporated GPT-3.5 Enterprise Bot was able to outperform the Microsoft stack.
Enterprise Bot responses tended to be:
- Most accurate.
- Shorter on average.
- Less likely to include hallucinations.
- More likely to provide a fallback response when the information couldn't be retrieved.
In addition, Enterprise Bot RAG offers many advantages over the Azure RAG and Aleph Alpha platforms.
DocBrain
Our RAG system is much easier to use and more flexible. Setting up Microsoft Azure AI RAG to ingest your company data is an expensive and time-consuming process, while DocBrain provides much higher-level controls to augment your agents with custom data.
Flexibility and future-proofing
Aleph Alpha is committed to developing their Luminos models while Azure RAG has an exclusive partnership with OpenAI. By contrast, you can easily switch Enterprise Bot RAG to use different models, such as GPT, Claude, or Llama 2. As new models are released, we evaluate them and make them available to Enterprise Bot customers at the push of a button.
Enterprise features
Azure RAG and Aleph Alpha give you the tools to build your own systems, but Enterprise Bot comes with features such as PII anonymization, low code integration, and conversational automation built in.
Book a demo to find out how we can help you with Enterprise-ready conversational automation today.